Le but est de caractériser le comportement d’une application sur l'infrastructure en vérifiant ses performances sur le réseau.
OPNET ACE (Application Characterization Environement) a pour but principal de déterminer pourquoi une application particulière ne donne pas entière satisfaction quant à ses performances sur le réseau. OPNET ACE utilise en entrée des traces capturées via des analyseurs de protocoles du marché ou via nos agents de captures logiciels OPNET ACE. Ces derniers peuvent être installés sur des postes clients et/ou serveurs et peuvent être commandés à distance afin de pouvoir démarrer des captures immédiatement si besoin. Etant donné que les agents ACE sont gratuits, on peut donc décider d’équiper tous les postes clients avec un tel agent afin de pouvoir réagir rapidement en cas de problème. Depuis la console de management des agents, il est possible de démarrer une capture en déclenchant les agents OPNET ACE en simultanée. Si l’application utilise par exemple 3 tiers (un client et deux serveurs), on pourra donc capturer les flux réseaux sur ces 3 tiers, les rapatrier sur la console de management afin de fusionner ensemble les différentes traces dans le but d’obtenir une vue d’ensemble du comportement de l’application sur le réseau. Dans le cas ci-dessous, les agents de captures OPNET sont installés sur la station de l'utilisateur de l'application, sur le serveur d'application et sur le serveur de bases de données.
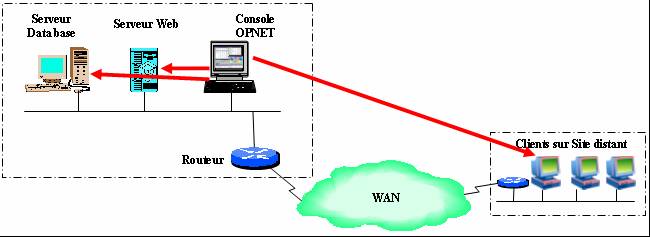
Il est possible de réaliser une capture à partir d'un routeur Cisco ayant un module NAM.
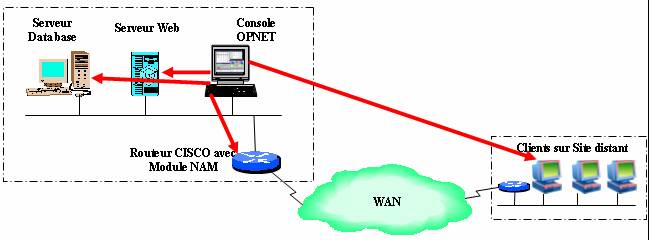
Il est possible de réaliser une capture à partir d'une sonde OPNET ACE live. ceci permet d'avoir une méthode de tests d'applications informatiques qui utilise une sonde réseau dont l'utilisation principale est le monitoring du réseau.
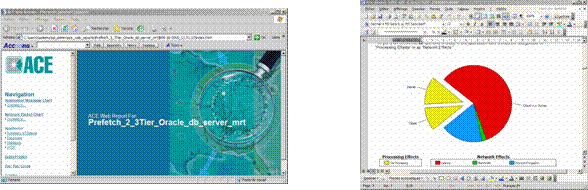
Une fois que la ou les transactions problématiques ont pu être capturé et importé dans ACE, la partie analyse des traces peut commencer. OPNET ACE dispose de plusieurs vues différentes permettant de rapidement isoler un comportement anormal. Une première visualisation appelée « Tier Pair Circle View » va donner des informations macroscopiques telles que le volume de trafic échangé entre tiers, le nombre de retransmissions,… :
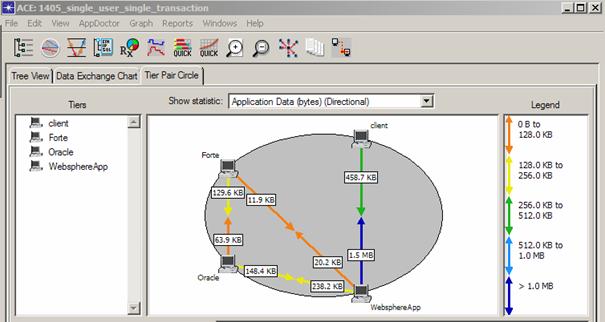
Volume de trafic applicatif échangé entre les différents tiers utilisés par l’application.
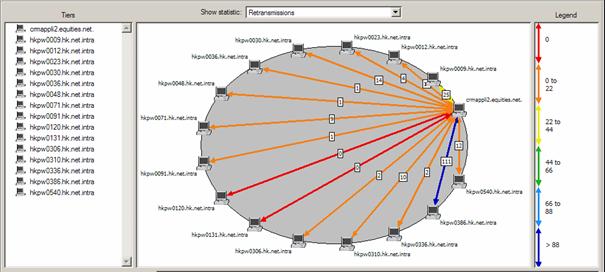
Nombre de retransmissions TCP entre un serveur et x clients. En bleu, 111 retransmissions entre le serveur et un client particulier, il conviendra donc de regarder de plus près le trafic entre ces deux tiers.
Une deuxième possibilité de visualisation est appelée « Data Exchange Chart » et va permettre de voir au cours du temps les échanges de messages applicatifs et réseaux entre tiers. L’image page suivante est divisée en 2 parties, celle du bas montre toutes les trames réseaux capturées (vue réseau) et celle du haut montre la reconstitution des messages applicatifs (ici un GET HTTP avec la réponse serveur) :
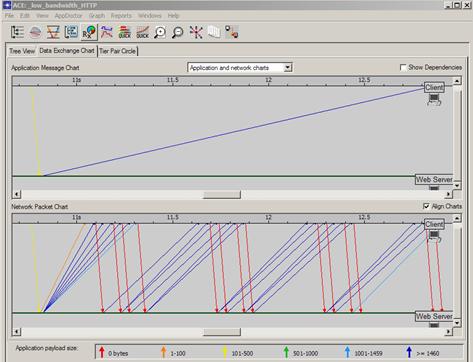
Le code couleur utilisée par défaut indique la charge utile transportée par chaque trame réseau (vue du bas). La couleur rouge correspondant à 0 octets de charge utile, on en déduit que les trames en question sont donc des ACK TCP envoyés par le client et l’on voit donc très bien ici comme la couche transport TCP travaille (i.e. attente d’acquittements avant envoi de multiples segments de data TCP).
Finalement, un troisième moyen de visualisation appelé « Tree View » est disponible avec par exemple, des informations spécifiques sur chaque requête élémentaire :
![]()
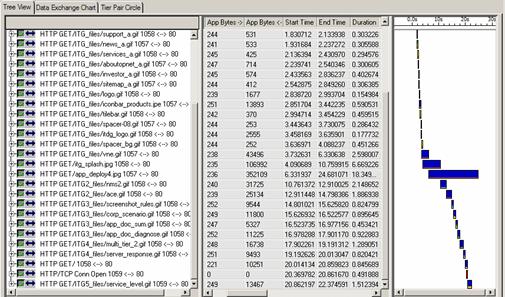
On remarque qu’il faut plus de 18 secondes pour récupérer l’image s’appelant « deploy4.jpg », celle-ci faisant environ 350 KB.
Ces différents moyens de visualisation graphiques sont d’une grande aide quand il s’agit d’essayer d’isoler les requêtes élémentaires pouvant être problématiques. Mais dire qu’il a fallu 18 secondes pour récupérer une n’est pas suffisant, il faut aussi essayer de décomposer le temps de transfert entre le temps passé au niveau « processing » des différents tiers et le temps passé sur le réseau pour transmettre l’objet. C’est le but de la fonctionnalité « AppDoctor » qui va automatiquement analyser la transaction problématique et faire cette décomposition pour nous. L’image suivante montre une telle décomposition pour une application trois tiers (client, serveur applicatif et base données) :
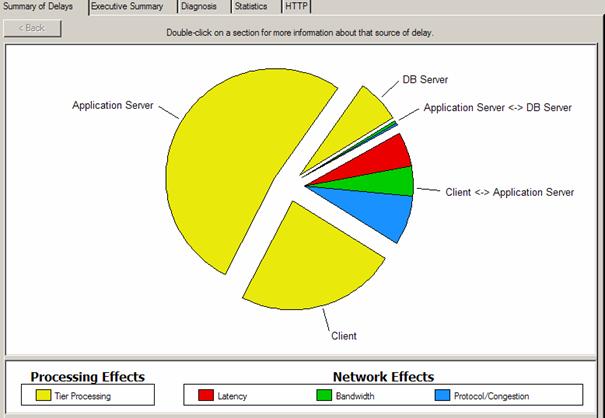
Les temps de « processing » en jaune (ici majoritaire) correspondent au temps passé dans les différents tiers avant de générer des trames sur le réseau. Les temps réseaux sont classés en trois domaines : Latence en rouge, c’est le temps de propagation des bits entre deux tiers et certaines applications mal écrites peuvent être très sensibles à ce paramètre ; Bande Passante en vert, i.e. le temps pour transmettre les bits sur le media, ici peu important et l’on voit immédiatement que doubler la bande passante entre deux tiers ne va pas vraiment améliorer les performances ; Protocol/Congestion, à savoir des problématiques de fenêtres TCP ou de retransmissions, le temps d’attente dans des queues avant partir sur un lien pour transmission.
Cette vue est l’élément principal d’ACE car il permet de montrer graphiquement où l’on perd du temps. Dans ce cas présent, plus de 75% du temps de réponse total est relatif à des temps de traitement machine, et le comportement réseau semble normal.
 De
plus, ACE va donner des pistes d’investigation supplémentaires en soulignant le
ou les paramètres pouvant expliquer pourquoi une transaction pose problème.
L’image page suivante montre le diagnostic automatique pour un trace avec
beaucoup de « bleu » dans la décomposition temps applicatif / temps
réseau :
De
plus, ACE va donner des pistes d’investigation supplémentaires en soulignant le
ou les paramètres pouvant expliquer pourquoi une transaction pose problème.
L’image page suivante montre le diagnostic automatique pour un trace avec
beaucoup de « bleu » dans la décomposition temps applicatif / temps
réseau :
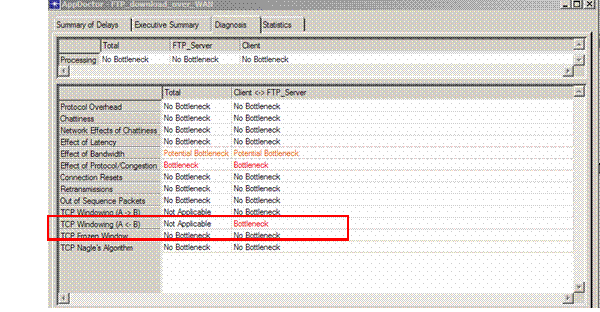
ACE a détecté un problème de taille de fenêtre TCP qui limite le débit de transfert. Des graphiques additionnels vont permettre de raffiner l’analyse :
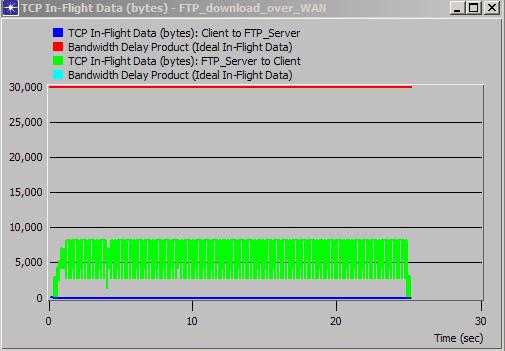
Ce graphe montre le nombre d’octets en cours de transfert géré par la couche de transport TCP. On ne dépasse pas 8 KB dans le sens serveur vers client (en vert) alors que le trait rouge indique la taille de fenêtre TCP qu’il faudrait utiliser au minimum pour que TCP ne soit pas un facteur limitant (i.e. 30 KB ou plus). Une augmentation de bande passante ne permettrait pas ici d’améliorer les performances, il faudra d’abord corriger le problème de la taille de fenêtre TCP utilisée.
De plus, des statistiques générales sont disponibles que le montre l’image page suivante :
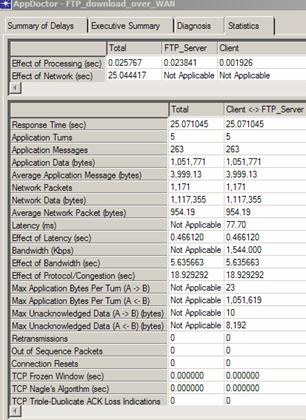
Dans le cas de protocoles tels que HTTP, CITRIX, SOAP ou CORBA, ACE fournira des statistiques spécifiques pour ces protocoles, par exemple pour HTTP, les types de commandes générées par le client, les codes de retours du serveur, le type et nombre d’objets contenus dans la page web, l’utilisation de techniques de « caching », de compression,... :
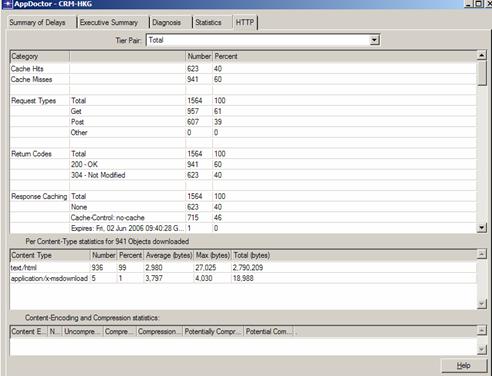
Concernant le décodage de protocoles, ACE par défaut ne décode que les protocoles TCP, UDP, IP, Ethernet et Token Ring. C’est pourquoi il est quasiment nécessaire d’ajouter le module ADM (Application Decode Module) qui va permettre de décoder plus de 700 protocoles tels que ceux cités juste avant. Il est également important de souligner qu’ADM est livré avec une API qui permettra de rajouter (soi même ou soi via consulting OPNET) des protocoles applicatifs propriétaires à condition bien sûr d’obtenir les spécifications du protocole à décoder.
Une fois le problème identifié, il est possible de tester des mesures correctives (tant au niveau applicatif qu’un niveau réseau) via la fonctionnalité « Quick Predict » d’ACE. Par exemple, on peut désirer montrer que doubler la bande passante minimale entre un client et un serveur ne va pas améliorer les performances s’il existe déjà un problème de fenêtre TCP comme dans l’exemple précédant :

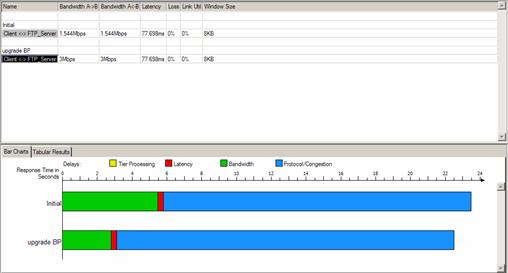
Doubler la bande passante à 3 Mbits n’est pas la bonne solution comme permet de le constater Quick Predict. Par contre, modifier la taille de fenêtre TCP pour la monter à 32 KB va avoir un effet immédiat sur les performances :
![]()
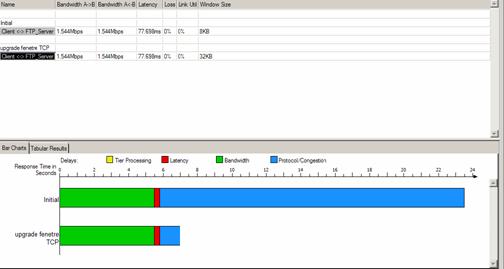
Le temps de réponse est divisé par un facteur trois dans ce cas.
Les changements réseaux possibles étant donc :
- bande passante minimale entre deux tiers
- latence
- pourcentage de pertes
- pré chargement du lien le plus faible du parcours
- taille de fenêtre TCP.
Au niveau applicatif, il sera également possible d’ajuster le comportement des flux échangés entre les différents tiers. Par exemple, diminuer le nombre d’allers retours de messages applicatifs pour des transactions de type base de données afin de réduire la sensibilité de l’application vis-à-vis de la latence :
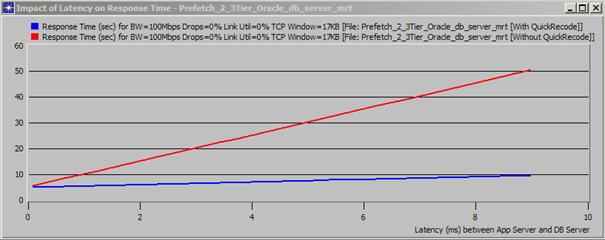
En rouge, la trace initiale et la prédiction du temps de réponse en fonction de la latence entre les deux tiers (de 0 à 10 ms). En bleu, la même prédiction suite au recodage applicatif de l’application (ici, demander des enregistrements au serveur de DB 20 par 20 au lieu de 2 par 2 comme c’était le cas dans la trace originale). On constate clairement qu’avec le recodage, l’application sera beaucoup moins sensible à la latence.
Finalement, il est important de noter que l’intégralité de l’analyse peut être exporté au format RTF et/ou HTML afin de publier de façon quasi immédiate des rapports qui pourront être transmis à qui de droit :
 |
La fonctionnalité « AppDoctor » vue plus haut va permettre de décomposer le temps de réponse total entre temps réseau et serveur. De plus, la capture étant faite au niveau réseau (capture des trames envoyées/reçues sur la carte réseau), de nombreux graphes orientés réseaux seront disponibles (débit pris par l’application, distribution des retransmissions, …) :
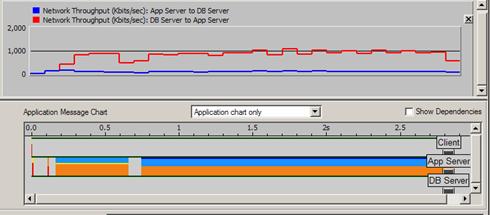
Il est assez fréquent de trouver également des temps de traitement serveur très long et qui par ailleurs sont la cause première de la dégradation des performances. L’image ci-dessous montre clairement un tel comportement :

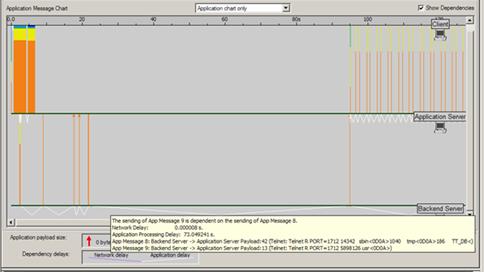
Le « Back End Server » traite une requête en interne durant plus de 73 secondes. Cela va suffire à innocenter le réseau mais si l’on désire aller plus loin dans l’analyse, il sera alors possible d’inclure des métriques systèmes capturées sur le serveur à partir de solutions telles que « Perfmon », « HP Glance plus », « Panorama » (notre solution de monitoring et de troubleshooting d’applications n-tiers) ou bien via un fichier de log exporté au format .csv. Dans ce cas, on pourra ajouter des graphes orientés systèmes comme l’utilisation CPU, mémoire, Entrées/Sorties disques, …, qui vont permettre de raffiner l’analyse :
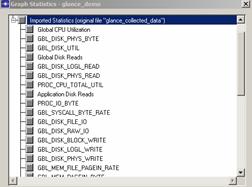
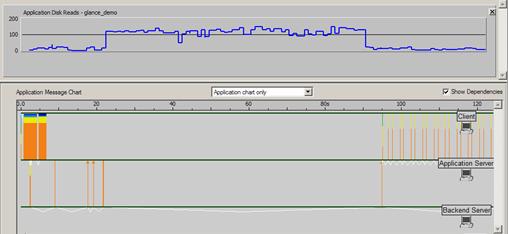
Le statistique ci-dessus est le nombre d’opérations de lecture sur disque effectuées par le « Back End Server » que l’on peut mettre en regard du temps de « processing » de 73 secondes.
L’intérêt d’utiliser une solution telle que Panorama avec ACE est qu’il est possible de synchroniser automatiquement la capture de trace faite dans ACE avec Panorama comme le montre la figure suivante, qui est celle permettant de démarrer la capture des agents ACE :
![]()
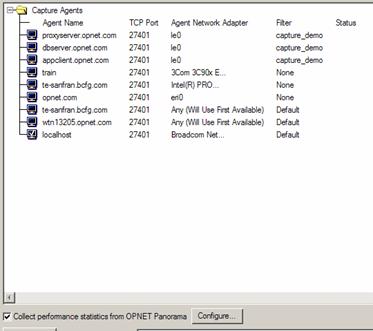
Lors de l’import des statistiques systèmes, la synchronisation temporelle entre les deux méthodes de capture (réseau avec ACE et système avec Panorama) sera automatique et il ne sera donc pas nécessaire de faire un ajustement manuel afin de présenter les statistiques au même instant.
C’est l’addition de ces deux solutions qui va permettre de fournir à la fois des statistiques réseaux et systèmes très précises pour une application donnée.